아키텍처
Immich는 데이터 지속성을 위한 전용 데이터베이스와 함께 전통적인 클라이언트-서버 디자인을 사용합니다. 프론트엔드 클라이언트는 HTTP를 사용하여 REST API를 통해 백엔드 서비스와 통신합니다. 아래는 아키텍처의 상위 수준 다이어그램입니다.
상위 수준 다이어그램
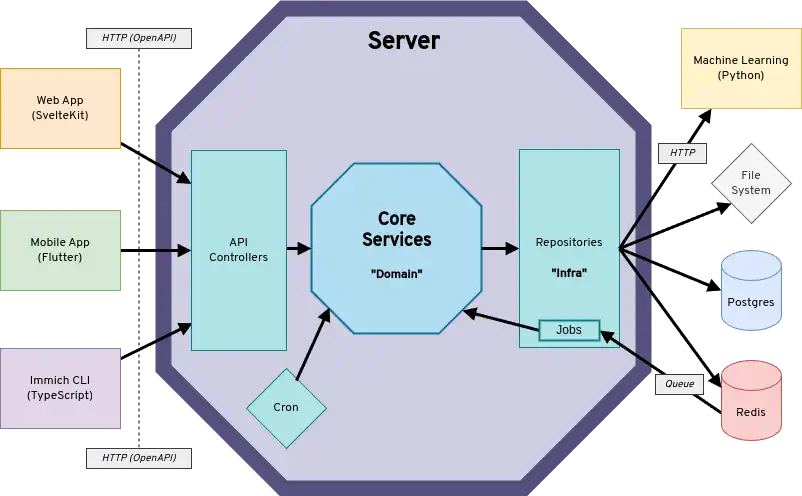
다이어그램은 클라이언트가 REST를 통해 서버 API와 통신하는 것을 보여줍니다. 서버는 저장소 인터페이스를 통해 다운스트림 시스템(예: Redis, PostgreSQL, 머신 러닝, 파일 시스템)과 통신합니다. 다이어그램에는 표시되지 않았지만, 서버는 immich-server와 immich-microservices라는 두 개의 별도 컨테이너로 분할되어 있습니다. 마이크로서비스 컨테이너는 API 요청을 처리하거나 크론 작업을 예약하지 않으며, 주로 Redis에서 들어오는 작업 요청을 처리합니다.
클라이언트
Immich는 세 가지 주요 클라이언트를 제공합니다:
- 모바일 앱 - Android, iOS
- 웹 앱 - 반응형 웹사이트
- CLI - 대량 업로드를 위한 명령줄 유틸리티
모바일 앱
모바일 앱은 Dart와 Flutter를 사용하여 작성되었습니다. 아래는 아키텍처 개요입니다:
다이어그램은 목표 아키텍처를 나타내며, 현재 코드 기반 상태는 항상 이 아키텍처를 따르지 않을 수도 있습니다. 새로��운 코드와 기여는 이 아키텍처를 따라야 합니다. 현재 Isar Database를 로컬 데이터베이스로, Riverpod을 상태 관리(프로바이더) 용도로 사용하고 있습니다. 데이터 클래스는 엔터티와 모델 두 가지 유형으로 사용됩니다. 엔터티는 디바이스 데이터베이스에 저장되지만, 모델은 휘발성으로 메모리에만 유지됩니다. 저장소는 다른 데이터 클래스를 내부적으로 사용하는 유일한 장소여야 합니다(예: OpenAPI DTO). 그러나 인터페이스는 외부 데이터 클래스를 사용하면 안 됩니다!
웹 클라이언트
웹 앱은 TypeScript 기반 프로젝트이며 SvelteKit 및 Tailwindcss를 사용합니다.
CLI
Immich CLI는 사용자가 명령줄에서 Immich 인스턴스를 제어할 수 있는 npm 패키지입니다. 이 패키지는 API를 사용해 다양한 작업, 특히 자산 업로드를 수행합니다. 자세한 사항은 CLI 문서를 참조하세요.
서버
Immich 백엔드는 여러 서비스로 나뉘며 각각 개별 Docker 컨테이너로 실행됩니다.
immich-server- REST API 요청 처리 및 응답, 백그라운드 작업 실행(썸네일 생성, 메타데이터 추출, 트랜스코딩 등)immich-machine-learning- 머신 러닝 모델 실행postgres- 지속적인 데이터 저장redis- 백그라운드 작업의 큐 관리
Immich 서버
Immich 서버는 TypeScript로 작성되었으며, Node.js를 위한 프로젝트입니다. 이 서버는 Nest.js 프레임워크, Express 서버, 그리고 쿼리 빌더 Kysely를 사용합니다. 서버 코드베이스는 느슨하게 헥사고날 아키텍처를 따릅니다. 구체적으로는, 기술에 특화된 구현(src/repositories)을 핵심 비즈니스 로직(src/services)과 분리하려고 합니다.
API 엔드포인트
들어오는 HTTP 요청은 컨트롤러(src/controllers)에 매핑됩니다. 컨트롤러는 HTTP 엔드포인트의 모음입니다. 각 컨트롤러는 일반적으로 해당 리소스 유형에 대한 다음 CRUD 작업을 구현합니다:
POST/<type>- 생성GET/<type>- 읽기 (전체)GET/<type>/:id- 읽기 (ID별)PUT/<type>/:id- 수정 (ID별)DELETE/<type>/:id- 삭제 (ID별)
도메인 전송 객체 (DTO)
서버는 각 엔드포인트의 입력(쿼리, 파라미터, 본문) 및 출력(응답)을 위한 공개 인터페이스로 도메인 전송 객체를 사용합니다. DTO는 OpenAPI 스키마로 변환되어 각 클라이언트에서 사용되는 생성된 코드를 제어합니다.
백그라운드 작업
Immich는 worker를 사용해 백그라운드 작업을 실행합니다. 이 작업에는 다음이 포함됩니다:
- 썸네일 생��성
- 메타데이터 추출
- 비디오 트랜스코딩
- 스마트 검색
- 얼굴 인식
- 저장소 템플릿 마이그레이션
- 사이드카 (참조: XMP Sidecars)
- 백그라운드 작업 (파일 삭제, 사용자 삭제)
이 목록은 관리 > 작업 페이지에서 사용할 수 있는 것과 거의 일치하며, 일부 원격 큐 관리 기능을 제공합니다.
머신 러닝
머신 러닝 서비스는 Python으로 작성되었으며 HTTP 통신을 위해 FastAPI를 사용합니다.
모든 머신 러닝 관련 작업은 이 서비스인 immich-machine-learning으로 외부화되었습니다. Python은 AI 및 머신 러닝에 적합한 선택입니다. 또한 특정 하드웨어 요구 사항도 충족합니다. 이를 별도의 컨테이너로 실행하면 해당 컨테이너를 별도의 기계에서 실행하거나 완전히 비활성화하기 쉽게 만듭니다.
머신 러닝 서비스에 대한 각 요청은 모델 작업, 모델 이름 등의 관련 메타데�이터를 포함합니다. 이러한 설정은 다른 시스템 구성과 함께 PostgreSQL에 저장됩니다. 요청마다 마이크로서비스 컨테이너는 이러한 설정을 가져와 요청에 첨부합니다.
내부적으로 머신 러닝 서비스는 지정된 모델을 다운로드, 로드 및 구성하여 텍스트 또는 이미지 페이로드를 처리합니다. 로드된 모델은 요청 간에 캐시되고 재사용됩니다. 스레드 풀을 사용해 각각의 요청을 별도의 스레드에서 처리하여 비동기 이벤트 루프를 차단하지 않습니다.
모든 모델은 ONNX 형식입니다. 이 형식은 폭넓은 산업 지원을 받아 대부분의 다른 모델 형식을 내보낼 수 있으며 많은 하드웨어 API에서 지원됩니다. 또한 상당히 빠릅니다.
머신 러닝 모델은 매우 크기 때문에 상당히 많은 메모리가 필요합니다. 우리는 항상 이 컨테이너의 이 부분을 개선하고 최적화할 방법을 찾고 있습니다.
PostgreSQL
Immich는 PostgreSQL에 데이터(액세스 및 인증 정보, 사용자, 앨범, 자산, 공유 설정 등)를 영구 저장합니다.
데이터베이스를 수정하여 인덱스를 생성, 테이블 수정, 새 열 추가 등을 하는 방법에 대한 자세한 내용은 Database Migrations를 참조하세요.
Redis
Immich는 BullMQ를 통해 Redis를 사용해 작업 큐를 관리합니다. 일부 작업은 후속 작업을 트리거합니다. 예를 들어, 스마트 검색과 얼굴 인식은 썸네일 생성에 의존하며 생성 후 자동으로 실행됩니다.