Architecture
Immich utilise une conception client-serveur traditionnelle, avec une base de données dédiée pour la persistance des données. Les clients frontend communiquent avec les services backend via HTTP en utilisant des API REST. Voici un diagramme de haut niveau de l'architecture.
Schéma de haut niveau
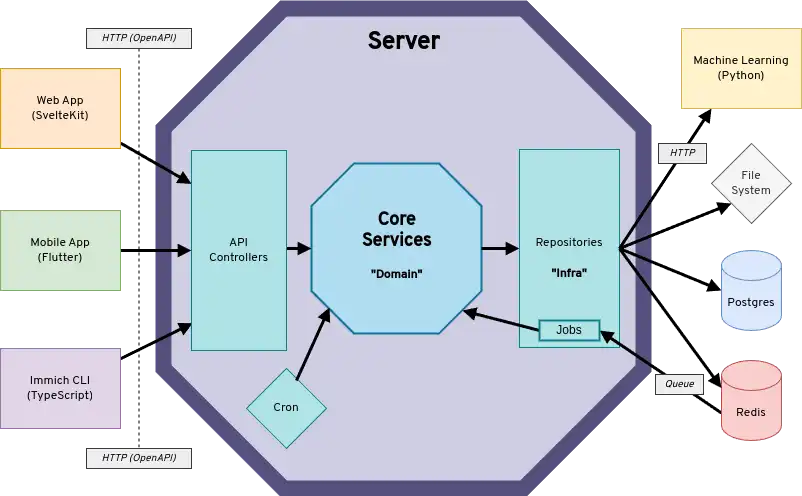
Le diagramme montre les clients communiquant avec l'API du serveur via REST. Le serveur communique avec les systèmes en aval (c'est-à-dire Redis, Postgres, Machine Learning, système de fichiers) via des interfaces de référentiel. Non représenté dans le diagramme, le serveur est divisé en deux conteneurs distincts immich-server et immich-microservices. Le conteneur microservices ne gère pas les requêtes API ni les travaux planifiés (cron jobs), mais s'occupe principalement des demandes de travaux entrants de Redis.
Clients
Immich a trois clients principaux :
- Application mobile - Android, iOS
- Application web - Site web réactif
- CLI - Utilitaire en ligne de commande pour les téléchargements en masse
Application mobile
L'application mobile est écrite en Dart en utilisant Flutter. Voici une vue d'ensemble de l'architecture :
Les diagrammes montrent l'architecture cible, l'état actuel de la base de code ne suit pas toujours encore cette architecture. Les nouveaux codes et contributions doivent suivre cette architecture. Actuellement, elle utilise Isar Database pour une base de données locale et Riverpod pour la gestion d'état (providers). Les entités et modèles sont les deux types de classes de données utilisées. Alors que les entités sont stockées dans la base de données sur l'appareil, les modèles sont éphémères et conservés uniquement en mémoire. Les référentiels devraient être le seul endroit où d'autres classes de données sont utilisées en interne (comme les DTO OpenAPI). Cependant, leurs interfaces ne doivent pas utiliser de classes de données étrangères !
Client web
L'application web est un projet TypeScript qui utilise SvelteKit et Tailwindcss.
CLI
Le CLI Immich est un package npm qui permet aux utilisateurs de contrôler leur instance Immich depuis la ligne de commande. Il utilise l'API pour effectuer diverses tâches, en particulier le téléchargement d'actifs. Voir la documentation CLI pour plus d'informations.
Serveur
Le backend Immich est divisé en plusieurs services, qui sont exécutés comme des conteneurs Docker individuels.
immich-server- Gère et répond aux requêtes API REST, exécute des tâches en arrière-plan (génération de vignettes, extraction de métadonnées, transcodage, etc.)immich-machine-learning- Exécute des modèles d'apprentissage automatiquepostgres- Stockage persistant des donnéesredis- Gestion des files d'attente pour les tâches en arrière-plan
Serveur Immich
Le serveur Immich est un projet TypeScript écrit pour Node.js. Il utilise le framework Nest.js, le serveur Express et le générateur de requêtes Kysely. La base de code du serveur suit également vaguement l'architecture hexagonale. Plus précisément, nous visons à séparer les implémentations spécifiques à la technologie (src/repositories) de la logique métier principale (src/services).
Points de terminaison API
Une requête HTTP entrante est mappée à un contrôleur (src/controllers). Les contrôleurs sont des collections de points de terminaison HTTP. Chaque contrôleur implémente généralement les opérations CRUD suivantes pour son type de ressource respectif :
POST/<type>- CréerGET/<type>- Lire (tout)GET/<type>/:id- Lire (par ID)PUT/<type>/:id- Mettre à jour (par ID)DELETE/<type>/:id- Supprimer (par ID)
Objets de transfert de domaine (DTO)
Le serveur utilise des objets de transfert de domaine comme interfaces publiques pour les entrées (requête, paramètres et corps) et les sorties (réponse) pour chaque point de terminaison. Les DTO se traduisent par des schémas OpenAPI et contrôlent le code généré utilisé par chaque client.
Tâches en arrière-plan
Immich utilise un travailleur pour exécuter des tâches en arrière-plan. Ces tâches incluent :
- Génération de vignettes
- Extraction de métadonnées
- Transcodage vidéo
- Recherche intelligente
- Reconnaissance faciale
- Migration du modèle de stockage
- Sidecar (voir XMP Sidecars)
- Tâches en arrière-plan (suppression de fichiers, suppression d'utilisateurs)
Cette liste correspond étroitement à ce qui est disponible sur la page Administration > Tâches, qui offre certaines capacités de gestion de file d'attente à distance.
Apprentissage automatique
Le service d'apprentissage automatique est écrit en Python et utilise FastAPI pour les communications HTTP.
Toutes les opérations liées à l'apprentissage automatique ont été externalisées vers ce service, immich-machine-learning. Python est un choix naturel pour l'IA et l'apprentissage automatique. Il a également des exigences matérielles assez spécifiques. L'exécuter en tant que conteneur séparé permet de l'exécuter sur une machine distincte, ou de le désactiver facilement complètement.
Chaque requête au service d'apprentissage automatique contient les métadonnées pertinentes pour la tâche du modèle, le nom du modèle, etc. Ces paramètres sont stockés dans Postgres avec d'autres configurations système. Pour chaque requête, le conteneur microservices récupère ces paramètres afin de les attacher à la requête.
En interne, le service d'apprentissage automatique télécharge, charge et configure le modèle spécifié pour une requête donnée avant de traiter le texte ou l'image avec celui-ci. Les modèles qui ont été chargés sont mis en cache et réutilisés entre les requêtes. Un pool de threads est utilisé pour traiter chaque requête dans un thread différent afin de ne pas bloquer la boucle d'événement asynchrone.
Tous les modèles sont au format ONNX. Ce format est largement pris en charge par l'industrie, ce qui signifie que la plupart des autres formats de modèles peuvent être exportés vers lui et que de nombreuses API matérielles le prennent en charge. C'est aussi assez rapide.
Les modèles d'apprentissage automatique sont également assez grands, nécessitant assez de mémoire. Nous cherchons toujours des moyens d'améliorer et d'optimiser cet aspect de ce conteneur en particulier.
Postgres
Immich persiste ses données dans Postgres, ce qui inclut des informations sur l'accès et l'autorisation, les utilisateurs, les albums, les actifs, les paramètres de partage, etc.
Voir Migrations de base de données pour plus d'informations sur la façon de modifier la base de données pour créer un index, modifier une table, ajouter une nouvelle colonne, etc.
Redis
Immich utilise Redis via BullMQ pour gérer les files d'attente des tâches. Certaines tâches déclenchent des tâches subséquentes. Par exemple, la recherche intelligente et la reconnaissance faciale dépendent de la génération de vignettes et s'exécutent automatiquement après qu'une vignette est générée.