Arquitetura
O Immich utiliza um design tradicional cliente-servidor, com um banco de dados dedicado para persistência de dados. Os clientes front-end se comunicam com os serviços back-end via HTTP usando APIs REST. Abaixo está um diagrama da arquitetura em alto nível.
Diagrama Detalhado
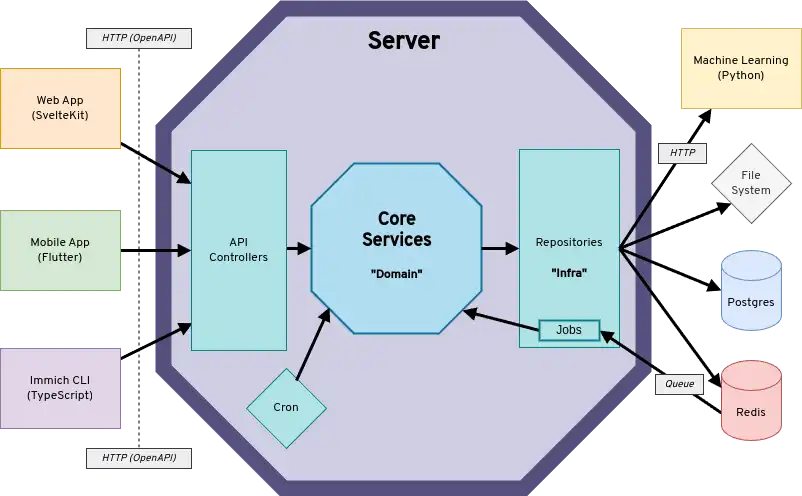
O diagrama mostra os clientes se comunicando com a API do servidor via REST. O servidor se comunica com sistemas downstream (como Redis, Postgres, Machine Learning e sistema de arquivos) por meio de interfaces de repositório. Não mostrado no diagrama, o servidor é dividido em dois contêineres separados: immich-server e immich-microservices. O contêiner de microservices não lida com solicitações de API ou agenda jobs no cron, mas lida principalmente com solicitações de trabalho recebidas do Redis.
Clientes
O Immich tem três principais clientes:
- Aplicativo móvel - Android, iOS
- Aplicativo web - Site responsivo
- CLI - Utilitário de linha de comando para upload em massa
Aplicativo móvel
O aplicativo móvel é escrito em Dart usando Flutter. Abaixo está uma visão geral da arquitetura:
Os diagramas mostram a arquitetura alvo. O estado atual da base de código nem sempre segue essa arquitetura ainda. Novos códigos e contribuições devem seguir essa arquitetura. Atualmente, utiliza Isar Database para banco de dados local e Riverpod para gerenciamento de estado (providers). Entidades e Modelos são os dois tipos de classes de dados utilizados. Enquanto entidades são armazenadas no banco de dados no dispositivo, os modelos são efêmeros e mantidos apenas na memória. Os Repositórios devem ser os únicos lugares onde outras classes de dados são usadas internamente (como DTOs do OpenAPI). No entanto, suas interfaces não devem usar classes de dados externas!
Cliente Web
O aplicativo web é um projeto em TypeScript que usa SvelteKit e Tailwindcss.
CLI
O CLI do Immich é um pacote npm que permite aos usuários controlarem sua instância Immich via linha de comando. Ele usa a API para realizar várias tarefas, especialmente o upload de arquivos. Veja a documentação do CLI para mais informações.
Servidor
O back-end do Immich é dividido em vários serviços, que são executados como contêineres individuais do Docker.
immich-server- Lida e responde a solicitações de API REST, executa tarefas em segundo plano (geração de miniaturas, extração de metadados, transcodificação, etc.)immich-machine-learning- Executa modelos de machine learningpostgres- Armazenamento persistente de dadosredis- Gerenciamento de filas para tarefas em segundo plano
Imich Server
O Immich Server é um projeto em TypeScript escrito para Node.js. Ele usa o framework Nest.js, o servidor Express e o construtor de queries Kysely. A base de código do servidor também segue, de forma ampla, a Arquitetura Hexagonal. Especificamente, buscamos separar implementações específicas da tecnologia (src/repositories) da lógica principal de negócio (src/services).
Endpoints da API
Uma solicitação HTTP recebida é mapeada para um controlador (src/controllers). Controladores são coleções de endpoints HTTP. Cada controlador geralmente implementa as seguintes operações CRUD para o respectivo tipo de recurso:
POST/<type>- CriarGET/<type>- Ler (todos)GET/<type>/:id- Ler (por id)PUT/<type>/:id- Atualizar (por id)DELETE/<type>/:id- Excluir (por id)
Objetos de Transferência de Domínio (DTOs)
O servidor usa Objetos de Transferência de Domínio como interfaces públicas para os dados de entrada (query, params e body) e saída (resposta) de cada endpoint. Os DTOs são traduzidos para esquemas OpenAPI e controlam o código gerado usado por cada cliente.
Tarefas em Segundo Plano
O Immich usa um trabalhador para executar jobs em segundo plano. Essas tarefas incluem:
- Geração de Miniaturas
- Extração de Metadados
- Transcodificação de Vídeo
- Pesquisa Inteligente
- Reconhecimento Facial
- Migração de Modelos de Armazenamento
- Sidecar (veja XMP Sidecars)
- Tarefas em segundo plano (exclusão de arquivos, exclusão de usuários)
Essa lista corresponde ao que está disponível na página Administração > Tarefas, que fornece algumas capacidades de gerenciamento remoto de filas.
Machine Learning
O serviço de machine learning é escrito em Python e utiliza FastAPI para comunicação via HTTP.
Todas as operações relacionadas à aprendizagem de máquina foram externalizadas para este serviço, immich-machine-learning. Python é uma escolha natural para IA e aprendizagem de máquina. Também possui requisitos de hardware bastante específicos. Executá-lo como um contêiner separado torna possível executar o contêiner em uma máquina separada ou desativá-lo facilmente.
Cada solicitação ao serviço de machine learning contém os metadados relevantes para a tarefa do modelo, nome do modelo, etc. Essas configurações são armazenadas no Postgres juntamente com outras configurações do sistema. Para cada solicitação, o contêiner de microservices recupera essas configurações para anexá-las à solicitação.
Internamente, o serviço de aprendizagem de máquina baixa, carrega e configura o modelo especificado para uma solicitação antes de processar o texto ou imagem com ele. Os modelos que foram carregados são armazenados em cache e reutilizados entre as solicitações. Um pool de threads é usado para processar cada solicitação em um thread separado, para não bloquear o loop de eventos assíncrono.
Todos os modelos estão no formato ONNX. Esse formato tem amplo suporte na indústria, o que significa que a maioria dos outros formatos de modelo podem ser exportados para ele e muitas APIs de hardware o suportam. Também é bastante rápido.
Os modelos de aprendizagem de máquina também são muito grandes, exigindo bastante memória. Estamos sempre procurando maneiras de melhorar e otimizar esse aspecto especificamente deste contêiner.
Postgres
O Immich armazena dados no Postgres, incluindo informações sobre acesso e autorização, usuários, álbuns, ativos, configurações de compartilhamento, etc.
Veja Migrações do Banco de Dados para mais informações sobre como modificar o banco de dados para criar um índice, modificar uma tabela, adicionar uma nova coluna, etc.
Redis
O Immich utiliza Redis por meio de BullMQ para gerenciar filas de tarefas. Algumas tarefas desencadeiam outras subsequentes. Por exemplo, a Pesquisa Inteligente e o Reconhecimento Facial dependem da geração de miniaturas e são executados automaticamente depois que uma é gerada.