Arquitectura
Immich utiliza un diseño tradicional cliente-servidor, con una base de datos dedicada para la persistencia de datos. Los clientes frontend se comunican con los servicios backend a través de HTTP utilizando APIs REST. A continuación, se muestra un diagrama de alto nivel de la arquitectura.
Diagrama de Alto Nivel
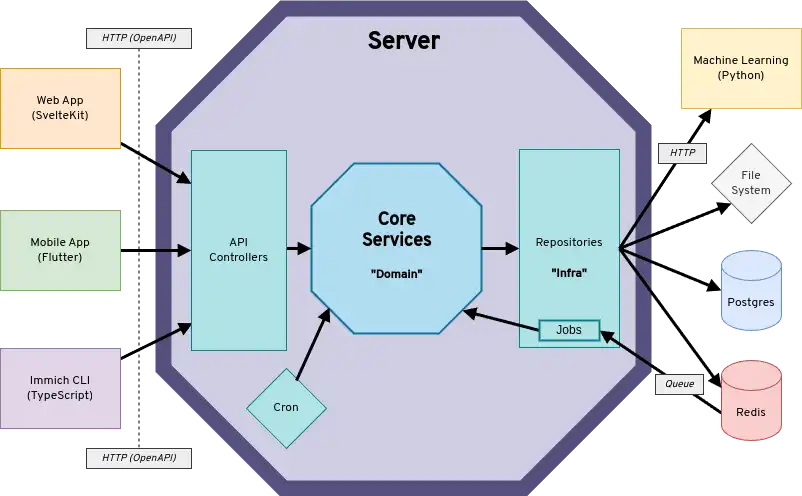
El diagrama muestra a los clientes comunicándose con la API del servidor a través de REST. El servidor se comunica con los sistemas descendentes (es decir, Redis, Postgres, Machine Learning, sistema de archivos) a través de interfaces de repositorio. No se muestra en el diagrama que el servidor está dividido en dos contenedores separados immich-server e immich-microservices. El contenedor de microservicios no maneja solicitudes de API ni programaciones cron, pero maneja principalmente solicitudes de trabajo entrantes desde Redis.
Clientes
Immich tiene tres clientes principales:
- Aplicación móvil: Android, iOS
- Aplicación web: Sitio web responsivo
- CLI: Herramienta de línea de comandos para cargas masivas
Aplicación Móvil
La aplicación móvil está escrita en Dart utilizando Flutter. A continuación, se muestra un resumen de la arquitectura:
Los diagramas muestran la arquitectura objetivo, aunque el estado actual de la base de código todavía no sigue completamente la arquitectura. El nuevo código y las contribuciones deben seguir este diseño. Actualmente, se utiliza Isar Database como base de datos local y Riverpod para la gestión de estados (providers). Se usan dos tipos de clases de datos: Entidades y Modelos. Si bien las entidades se almacenan en la base de datos del dispositivo, los modelos son efímeros y solo se mantienen en memoria. Los Repositorios deberían ser el único lugar donde otras clases de datos se usen de forma interna (como los DTOs de OpenAPI). Sin embargo, sus interfaces no deben utilizar clases de datos externas.
Cliente Web
La aplicación web es un proyecto de TypeScript que utiliza SvelteKit y Tailwindcss.
CLI
El CLI de Immich es un paquete de npm que permite a los usuarios controlar su instancia de Immich desde la línea de comandos. Utiliza la API para realizar varias tareas, especialmente la carga de recursos. Consulta la documentación de CLI para más información.
Servidor
El backend de Immich se divide en varios servicios, que se ejecutan como contenedores Docker individuales.
immich-server: Maneja y responde a solicitudes de API REST, ejecuta trabajos en segundo plano (generación de miniaturas, extracción de metadatos, transcodificación, etc.)immich-machine-learning: Ejecuta modelos de machine learningpostgres: Almacenamiento persistente de datosredis: Gestión de colas para trabajos en segundo plano
Servidor Immich
El servidor Immich es un proyecto de TypeScript escrito para Node.js. Utiliza el marco Nest.js, el servidor Express y el constructor de consultas Kysely. El código del servidor también sigue, de forma aproximada, la Arquitectura Hexagonal. Específicamente, buscamos separar las implementaciones tecnológicas específicas (src/repositories) de la lógica central de negocio (src/services).
Puntos de API
Una solicitud HTTP entrante se asigna a un controlador (src/controllers). Los controladores son colecciones de puntos finales HTTP. Cada controlador usualmente implementa las siguientes operaciones CRUD para su tipo de recurso respectivo:
POST/<type>- CrearGET/<type>- Leer (todos)GET/<type>/:id- Leer (por id)PUT/<type>/:id- Actualizar (por id)DELETE/<type>/:id- Eliminar (por id)
Objetos de Transferencia de Dominio (DTOs)
El servidor utiliza Objetos de Transferencia de Dominio como interfaces públicas para las entradas (consulta, parámetros y cuerpo) y salidas (respuesta) de cada punto final. Los DTOs se traducen a esquemas de OpenAPI y controlan el código generado usado por cada cliente.
Trabajos en Segundo Plano
Immich usa un trabajador para ejecutar trabajos en segundo plano. Estos trabajos incluyen:
- Generación de miniaturas
- Extracción de metadatos
- Transcodificación de video
- Búsqueda inteligente
- Reconocimiento facial
- Migración de plantillas de almacenamiento
- Sidecar (ver XMP Sidecars)
- Trabajos en segundo plano (eliminación de archivos, eliminación de usuarios)
Esta lista coincide con lo que está disponible en la página Administración > Trabajos, que brinda algunas capacidades de gestión de colas de forma remota.
Machine Learning
El servicio de machine learning está escrito en Python y utiliza FastAPI para la comunicación por HTTP.
Todas las operaciones relacionadas con machine learning se han externalizado a este servicio, immich-machine-learning. Python es una elección natural para la inteligencia artificial y machine learning. También tiene requisitos de hardware bastante específicos. Ejecutarlo como un contenedor separado permite ejecutarlo en una máquina distinta o desactivarlo fácilmente.
Cada solicitud al servicio de machine learning contiene los metadatos relevantes para la tarea del modelo, el nombre del modelo, etc. Estas configuraciones se almacenan en Postgres junto con otras configuraciones del sistema. Para cada solicitud, el contenedor de microservicios recupera estas configuraciones para adjuntarlas a la solicitud.
Internamente, el servicio de machine learning descarga, carga y configura el modelo especificado para una solicitud determinada antes de procesar con él la carga de texto o imagen. Los modelos que han sido cargados se almacenan en caché y se reutilizan en múltiples solicitudes. Un grupo de subprocesos se utiliza para procesar cada solicitud en un hilo diferente para no bloquear el bucle de eventos asíncrono.
Todos los modelos están en formato ONNX. Este formato tiene un amplio soporte en la industria, lo que significa que la mayoría de otros formatos de modelo se pueden exportar a él y muchas APIs de hardware lo admiten. También es bastante rápido.
Los modelos de machine learning también son bastante grandes, lo que requiere bastante memoria. Siempre estamos buscando formas de mejorar y optimizar este aspecto de este contenedor en particular.
Postgres
Immich persiste los datos en Postgres, lo que incluye información sobre acceso y autorización, usuarios, álbumes, recursos, configuraciones de uso compartido, etc.
Consulta Migraciones de base de datos para obtener más información sobre cómo modificar la base de datos para crear un índice, modificar una tabla, agregar una nueva columna, etc.
Redis
Immich utiliza Redis a través de BullMQ para gestionar colas de trabajos. Algunos trabajos desencadenan otros consecutivos. Por ejemplo, la búsqueda inteligente y el reconocimiento facial dependen de la generación de miniaturas y se ejecutan automáticamente después de que se genera una.